Wanneer de data uit een is geïndexeerd, en de configuratie(s) voor de data goed zijn ingesteld, is het mogelijk een trend analyse uit te voeren. Hierbij wordt gekeken naar de data per dag, worden gemiddelden berekend over langere tijd, en wordt het verloop van bepaalde indicatoren over langere tijd in beeld gebracht.
Selectie van dagen
Om een trend analyse uit te kunnen voeren moet eerst een selectie van dagen worden gemaakt die in de analyse moeten worden meegenomen. Het maken en bewerken van de selectie gaat middels de knoppen boven de kalender-lijst met de beschikbaarheid.
Let op: in de lijst en de kalender is het óók mogelijk een dag te selecteren (in bovenstaande afbeelding is dit ook zo: de geselecteerde dag is blauw gearceerd). Die selectie heeft uitsluitend als effect dat van de betreffende dag de meta data wordt weergegeven onder het kopje “Geselecteerde dag”, en de fasenlog-preview wordt geladen (zie hier). Deze selectie staat dus geheel los van de selectie van dagen t.b.v. de trend analyse.
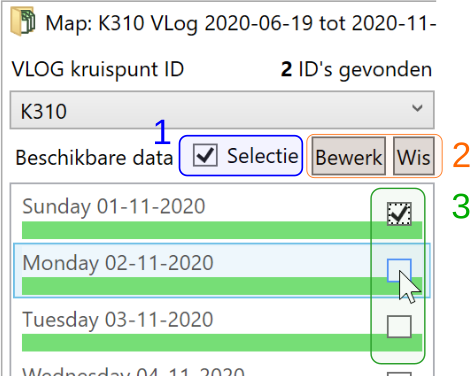
Om een selectie van dagen te maken gaan we als volgt te werk (de cijfer refereren naar de afbeelding hier boven):
Vink “Selectie” aan boven de kalender-lijst (1), zodat er een vinkje per dag (3) zichtbaar wordt.
Het is nu mogelijk handmatig per dag het vinkje te zetten (3)
Doorgaans is het makkelijker middels de knop “Bewerk” (2) de selectie van dagen middels criteria op te bouwen. Er verschijnt dan een dialoogvenster:
Kies start en einde datum. Let op dat over de betreffende periode één configuratie geldig moet zijn.
Kies de verdere criteria, zoals mate van compleetheid, dag type en evt. welke maanden wel/niet meegenomen moeten worden
Klik op “OK”, de selectie wordt nu gemaakt
Merk op: maken van een selectie via het dialoogvenster dit werkt óók wanneer het vinkje “Selectie” uit staat, echter is de selectie dan niet zichtbaar.
Uitvoeren trend analyse
Tijdens het uitvoeren van de trend analyse bepaalt YAVV van diverse waarden de totale en gemiddelde waarde voor de gehele dag. De perioden waarvoor dit gebeurt zijn instelbaar. Optioneel is mogelijk reguliere analyse data per dag op te halen.
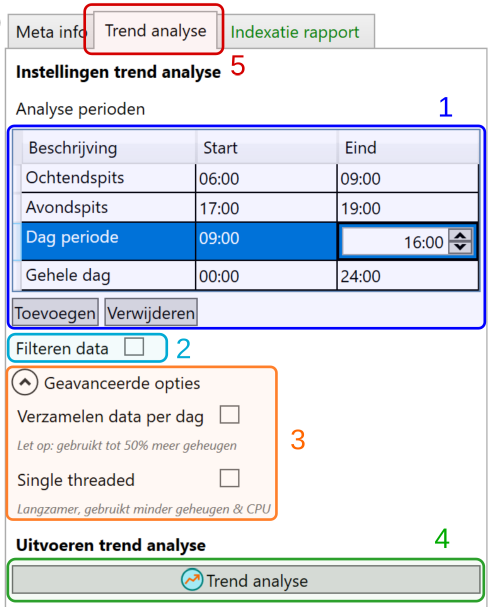
Via de tab “Trend analyse” (bij 5 zoals hieronder te zien) komen de opties voor de analyse in beeld.
Momenteel zijn de volgende opties beschikbaar (de nummers refereren naar de afbeelding):
Instellen perioden (1) waarvoor de trend analyse zal worden uitgevoerd. Na uitvoeren van de analyse kunnen de uitkomsten afzonderlijk per ingestelde periode worden bekeken.
Gebruik de knoppen om periode toe te voegen of te verwijderen
Klik op de tijd om die in te stellen
Maak gebruik van defaults: via menu Help > Instellingen YAVV > Big data; wat daar is ingesteld verschijnt in dit tabblad als default voor de perioden.
Filteren data (2): al dan niet gebruik maken van filtering van data tijdens uitvoeren van de analyses
Geavanceerde opties (3):
Verzamelen data per dag: indien aangevinkt, verzamelt YAVV tijdens de trend analyse voor iedere dag ook (per periode) de reguliere analyse uitkomsten. Na de analyse kan hier snel doorheen worden gebladerd, en data naar wens worden geëxporteerd. Let op: dit kost zeker bij meerdere perioden en veel dagen significant meer werkgeheugen.
Single threaded: normaal gesproken voert YAVV de trend analyse zo snel mogelijk uit, waarbij meerdere dagen gelijktijdig worden doorgerekend. Indien aangevinkt, zorgt dit ervoor dat de trend analyse dag na dag, dus met een enkel (achtergrond)proces gebeurt. Dit kost beduidend meer tijd, maar kost in de regel ook minder werkgeheugen.
Na klikken op “Trend analyse” (4) opent YAVV een nieuw werkblad en gaat de analyse lopen. Dit duurt afhankelijk van de aard van de data (grote of kleine kruising), het aantal te analyseren dagen en de specificaties van de hardware van de betreffende pc, tussen enkele seconden en meerdere minuten. De applicatie geeft een indicatie van de voortgang.
Let op: indien de applicatie langdurig stil blijft staan gaat er mogelijk iets mis met de analyse. YAVV kan met veel data omgaan, maar de ervaring leert dat er met VLOG data toch nog onverwachte punten de kop op kunnen steken.
Uitkomsten trend analyse
Na uitvoeren van een trend analyse is de volgende data beschikbaar:
Gemiddelde waarden voor alle analyses
Een overzicht met totalen per periode per dag voor een aantal indicatoren
Indien ingeschakeld: reguliere analyse data per dag
Gemiddelden
Hier zijn per ingestelde periode per analyse gemiddelde resultaten op te vragen. Niet alle in YAVV aanwezige analyses komen hier terug; zaken als check naloop of analyses rond C-ITS data doen hier niet mee. Links in beeld kunnen periode, categorie en analyse ingesteld worden.
De weergave van analyse data is verder gelijk aan die van YAVV bij het werken met data uit bestanden, echter komen er nu ook getallen achter de komma voor waar dit normaliter niet zo is (bv.: intensiteiten, roodrijders, etc.). Waar van toepassing worden analyse resultaten herberekend (bv.: capaciteit, groenbenutting).
Trend
Onder “Trend overzicht” is het verloop van een aantal indicatoren over de geselecteerde periode te zien. Hiermee kan bv. snel inzichtelijk worden gemaakt wanneer het een dag of week drukker of juist rustiger was in een langere periode. De volgende indicatoren zijn momenteel beschikbaar:
Totale intensiteit per richting
Gemiddelde wachttijd eerstwachtende
Cyclustijd
Ook hier kan een periode gekozen worden, alsook het type analyse om weer te geven.
Data per dag
Indien dit is ingeschakeld is ook data per dag op te vragen. Dit is dus dezelfde data als wanneer de data per dag in YAVV zou worden ingeladen en de analyse met de hand uitgevoerd zou worden. Echter nu gebeurt dit in één keer voor een bulk geselecteerde dagen.
Ook hier wordt weer de periode gekozen, de categorie en het type analyse. Middels de lijst met data links in beeld kan door de dagen heen gebladerd worden. De weergave verdere is identiek aan de reguliere analyse weergave. Instelling in de weergave blijven behouden wanneer van dag of periode wordt gewisseld.
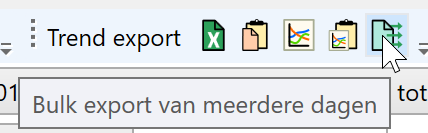
Middels dit tabblad kan snel door data heen worden gebladerd. Tevens zijn er uitgebreide export mogelijkheden:
In het dialoogvenster voor bulk export kan worden ingesteld voor welke periode en welke analyse data moet worden geëxporteerd. Tevens is het interval instelbaar, en kan worden gekozen data per dag of als geheel te exporteren. Het resultaat is per periode, per analyse en al dan niet per dag een .csv bestand met de data.
Bij VLOG data hoort altijd een configuratie. Dit kan zijn een .cfg/.vlg/.vlt bestand, of in geval van VLOG3 zit de configuratie doorgaans elk uur in de data opgenomen. Aanvullend voor analyse doeleinden is informatie nodig over ligging van lussen, welke lus bij welke fase hoort en evt. instellingen voor analyses.
T.b.v. juist uit kunnen voeren van trend analyses is het van belang dat YAVV beschikt over de juiste configuratie(s). Dit artikel gaat in op de manier waarop YAVV/bd om gaat met configuraties, en wat de gebruiker moet doen om te zorgen dat dit goed verloopt.
Herkennen van configuraties
Tijdens de indexatie van data bepaalt YAVV voor elk bestand:
aantal signaalgroepen
aantal detectoren
aantal ingangen
aantal uitgangen
Elke unieke combinatie van deze aantallen geldt binnen deze context als “configuratie”. Puur de aantallen IO elementen is als configuratie natuurlijk niet heel nuttig, dit wordt vervolgens aangevuld (zie volgende alinea). Kijken naar aantallen IO is slechts een manier voor YAVV/bd om te bepalen of en waar er sprake is van wijzigingen. Omdat VLOG werkt met index nummers, is dit belangrijk: bij gewijzigde index nummers gaat het anders mis met toedeling van event en analyse resultaten aan bijvoorbeeld fasen en detectoren.
Na indexatie worden bestanden op volgorde gezet op basis van de startdatum/tijd van de inhoud van de data. Vervolgens wordt gekeken of er gegeven de configuratie bij de start van de data, wijzigingen plaatsvinden in de aantallen IO. Is dit het geval, dan wordt een nieuwe configuratie aangemaakt. Dit levert dus op:
Een lijst met configuraties met elk een start en einde datum/tijd.
Elke configuratie in de lijst krijgt eigen instellingen v.w.b. naamgeving van elementen, toedeling van detectoren, analyses, etc.
Elke configuratie heeft één bereik in de tijd waarop deze van toepassing is. Ook wanneer een eerdere configuratie weer geldig zou kunnen worden wordt dus een nieuwe aangemaakt bij een wijziging.
Instellingen voor configuraties
Wanneer de in de data aanwezige configuraties zijn bepaald moeten deze juist worden ingesteld, t.b.v. van bv. weergave van de (preview) fasenlog en met name uitvoeren van trend analyses. YAVV doet een poging de beste instellingen in te laden, de gebruiker moet dit wel controleren.
Automatisch zoeken naar instellingen
Net als wanneer met YAVV bestanden worden geopend (zie hier), zoekt ook YAVV/bd automatisch naar de best passende configuratie. Hierbij geldt:
Bij VLOG3 data wordt de configuratie uit de data zelf default ingeladen.
Vervolgens wordt gezocht naar .yavv, .cfg, .vlt en .vlc bestanden in de geopende map – inclusief onderliggende mappen! Tevens wordt gezocht naar degelijke bestanden in de default configuratie map – indien ingesteld. Het resultaat is een complete lijst met beschikbare configuratie instellingen.
Vervolgens wordt een match gezocht – waarbij naast de naam van het bestand ook de aantallen IO moeten matchen:
Als eerste een 1 op 1 match tussen TLC-id uit de data en bestandsnaam voor .yavv bestanden
Dan een partiële match voor .yavv bestanden
Vervolgens een 1 op 1 match tussen de TLC-id uit de data en een CFG bestand (.cfg, .vlc of .vlt)
En tenslotte een partiële match met een CFG bestand
Per voorgaande stap worden telkens eerst configuratie bestanden uit de geopende map geprobeerd, en daarna evt. bestanden uit de default configuratie map.
De eerst gevonden match zorgt voor toepassen van de betreffende configuratie en afbreken van het zoekproces.
Bewerken van configuraties
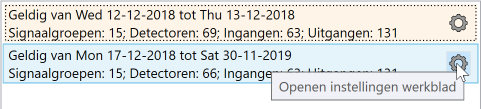
Configuraties kunnen worden bewerkt door in de lijst met configuratie op het tandwiel van de betreffende configuratie te klikken.
Hiermee wordt een nieuw werkblad geopend, waarin de configuratie kan worden bewerkt. Het is middels de knoppen in de toolbar ook mogelijk een configuratie bestand te gebruiken om instellingen in te laden. Tevens is het mogelijk de (al dan niet aangepaste) configuratie instellingen op schijf op te slaan.
Toepassingsbereik van configuraties
Configuraties hebben een vast gebied in de tijd waarop deze van toepassing zijn. In de lijst kan een configuratie worden geselecteerd, maar dit heeft momenteel geen verder effect – die mogelijkheid hoort eenvoudigweg bij het feit dat dit een lijst is.
Dit houdt dus in:
Configuraties hebben een vaste start en einde datum/tijd voor wat betreft hun geldigheid.
Selectie van een configuratie in de lijst heeft geen effect.
Bewerken van een configuratie heeft alleen effect op een analyse die nadien wordt uitgevoerd voor een tijdbestek dat valt binnen start en einde geldigheid van de betreffende configuratie.
Tevens is goed om te weten (vooruitlopend op het uitvoeren van trend analyses link=TODO):
Een trend analyse kan enkele worden uitgevoerd over een tijdsperiode waarop één unieke configuratie van toepassing is.
Dit is nodig, omdat wordt gewerkt met indices. Wijzigen de indices, dan wijzigt mogelijk de toedeling.
Dagen waarop meer dan één configuratie actief zijn, kunnen niet mee doen in de trend analyse – immers: het is onzeker of data voor index x altijd hetzelfde werkelijke item betreft.
Dit artikel gaat in op de praktijk van het indexeren van data met de big-data addon voor YAVV. Voor een introductie en enige achtergrond informatie over deze addon: zie hier.
Vooraf: eisen aan de brondata
YAVV/bd kan het nodige aan qua vorm en inhoud van de brondata. Toch zijn er enkele uitgangspunten en eisen om rekening mee te houden.
Uitgangspunt is data per dag. Dat wil zeggen dat er per dag één of meer bestanden zijn. YAVV/bd kan niet om gaan met data waarbij binnen één bestand data van meerdere dagen zit.
Op termijn is de bedoeling voorbewerken van data mogelijk te maken binnen YAVV. Heeft u hier interesse in, neem dan contact op.
Indien er overlap in de data zit, wordt het (deels of geheel) overlappende bestand niet gebruikt. Dit is in te zien via het indexatie rapport.
Bij corrupte data (bv.: onvolledige berichten) of data waarbij binnen één bestand de tijd meer dan een uur terugloopt, wordt het betreffende bestand als corrupt aangemerkt en niet gebruikt. Dit is eveneens in te zien via het indexatie rapport.
Houdt er rekening mee dat alle VLOG data, inclusief data in onderliggende mappen, wordt geïndexeerd. Tevens wordt in alle mappen gezocht naar configuratie files.
Tenslotte: YAVV/bd kijkt in de bestanden, de bestandsnaam doet niet ter zake. De tijd/datum alsook TLC-id (naam van de kruising) in de bestandsnaam wijkt soms af van de tijd/datum en TLC-id in de data. Voor YAVV is de inhoud, dus de tijd/datum en TLC-id uit de data, de maat der dingen. De bestandsnaam wordt niet als databron benut.
Indexatie: de basis
Het indexeren gaat door te klikken op de knop “Openen map” op de toolbar en vervolgens de betreffende map te kiezen.
Tip: de map kan in het dialoogvenster geselecteerd worden in de lijst, maar wat ook werkt: wanneer de map in het dialoogvenster open staat, en in die map is verder niets geselecteerd. In het laatste geval zorgt een klik op OK ook voor selectie van de betreffende map.
Na de selectie van de map begint YAVV met de indexatie. Al naar gelang de hoeveeelheid data duurt dit langer of korter. Het proces is zo ingericht dat bij aanwezigheid van meer detectoren, er parallel wordt gewerkt. De applicatie geeft een indicatie van de voortgang.
Let op: omdat de indexatie veel systeembronnen vergt, kan het zijn dat YAVV gedurende de indexatie wat minder responsief is.
Wanneer de indexatie klaar is verschijnt een weergave van de gevonden data. Dit wordt hieronder toegelicht.
Opslag van de indexatie
Het is mogelijk de indexatie op te slaan, zodat het een volgende keer minder lang duurt om de map te openen in YAVV. Zeker bij zeer grotere datasets kan dit veel tijd schelen. Klik hiertoe op de knop op de toolbar “Opslaan indexatie”, kies de locatie en geef de bestandsnaam op.
Om een opgeslagen indexatie te openen is er eveneens een knop op de toolbar beschikbaar (). Wanneer een opgeslagen indexatie wordt geopend.
Controleert YAVV of de in de indexatie aanwezige VLOG files overeen komen met de aanwezig VLOG files op schijf. Wordt een afwijking gevonden, dan vraagt de applicatie of opnieuw geïndexeerd moet worden.
Zoekt YAVV naar relevante configuraties – deze zijn dus niet vastgelegd in of gekoppeld aan de indexatie!
Voert YAVV opnieuw de toedeling van data aan kruispunten, en bepaling van beschikbaarheid van data uit, tbv. weergave aan de gebruiker.
Deze acties kosten ook (reken)tijd, maar een veelvoud minder dan een complete indexatie.
Let op: momenteel wordt het pad van de geïndexeerde map als absoluut pad opgeslagen in de indexatie. Hierdoor kan de index om het even waar worden opgeslagen, maar is de index dus niet verplaatsbaar inclusief data.
Let op: bij zeer grote hoeveelheden data kan YAVV na het openen van de index kort niet responsief zijn. De reden is dat het openen van de index momenteel niet op de achtergrond gebeurt.
Het indexatie tabblad
Na indexatie is per gevonden kruispunt zichtbaar welke data beschikbaar is, en kan een selectie worden gemaakt van dagen t.b.v. trend analyse.
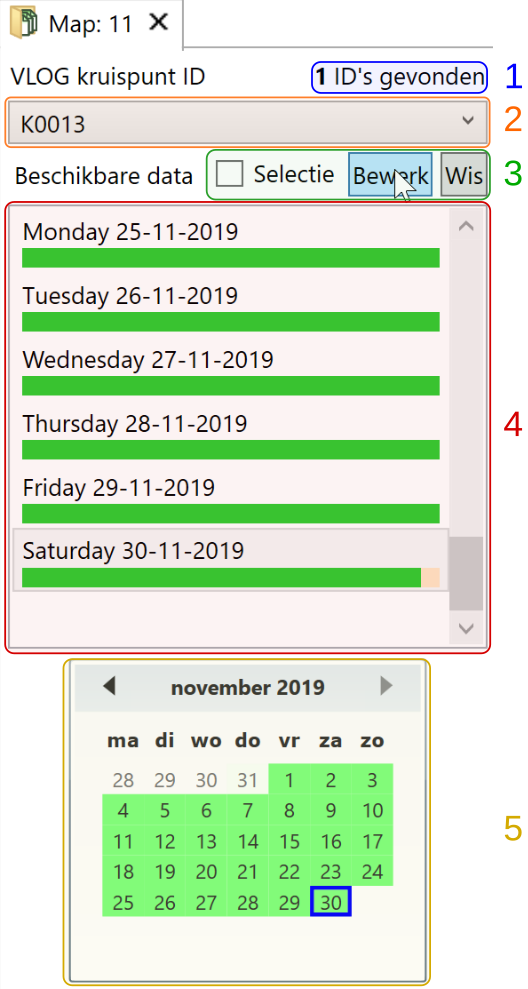
Hiernaast is het meest linker gedeelte van het indexatie tabblad te zien. Hier een beknopte omschrijving van de onderdelen:
Aantal gevonden TLC id’s (kruispunt namen uit de VLOG data)
Selectie actieve TLC id
Bewerken selectie van dagen
Beschikbare data voor actuele maand
Kalender t.b.v. manouvreren in de tijd
De toedeling van data aan een kruispunt gebeurt op basis van het kruispunt ID zoals dit in de VLOG data wordt gevonden. Het aantal gevonden ID’s (1) is te zien naast boven de combobox (2). Via de combobox (2) kan worden gewisseld tussen kruispunten.
Tip: lijkt data te ontbreken voor een kruispunt? Controleer altijd eerst of de data wellicht onder een andere TLC id toch is geïndeerd.
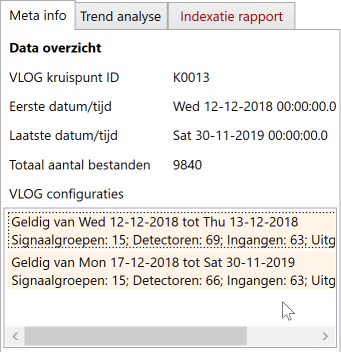
Van de geselecteerde kruispunt wordt naast de combobox onder tabblad “Meta info” onder het kopje “Data overzicht” weergegeven tussen welke minimale en maximale tijd/datum er data is gevonden, en hoeveel bestanden zijn geïndexeerd. Tevens worden de gevonden configuraties weergegeven.
Beschikbare data
Onder de combobox wordt de beschikbaarheid van data in de tijd weergegeven. In de lijst (4) wordt dit weergegeven van één maand, namelijk de maand behorende bij de actueel geselecteerde dag. Na indexatie wordt default de laatst beschikbare dag geselecteerd, en komt dus de maand waarin die dag valt in beeld in de kalender-lijst en kalender daaronder.
In de lijst is per dag aan de groene streep te zien is welke data beschikbaar is. Met een tooltip (te zien door de muis kort te laten zweven boven een dag) zijn details te zien van de beschikbaarheid.
Onder de lijst is een kleine kalender te zien (5). Middels de kalender is het mogelijk te manouvreren in de tijd. Bij wisseling naar een andere maand wordt ook de lijst (4) boven de kalender ververst met de dagen van die maand. Met klikken kan ook worden “uitgezoomd” zodat gemakkelijk en efficient naar een andere maand (of jaar) kan worden gesprongen.
De knoppen bij 3 zijn van belang voor het maken van een selectie van dagen t.b.v. uitvoeren van een trend analyse.
Data per dag
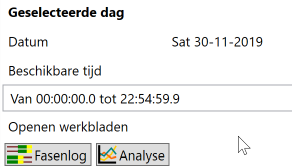
Selectie van een dag in de lijst of in de kalender (middels een muisklik, de dag kleurt dan blauw gearceerd zo lang de focus daar is, anders grijs) zorgt ervoor dat naast de kalender onder de kop “Geselecteerde dag” informatie omtrent die dag wordt weergegeven.
Tevens wordt rechts in beeld een preview geladen van de fasenlog voor die dag. De preview werkt net als de reguliere fasenlog, maar veel zaken zijn momenteel niet instelbaar. In de toekomst is de bedoeling bv. toedelen van detectoren aan fasen, zoom, en keuze voor GUW en/of WUS ook hier toegankelijk te maken.
Fasenlog en analyse per dag
Het is mogelijk voor de geselecteerde dag extra werkbladen te openen middels de knoppen “Fasenlog” en “Analyse”.
Let op: klikken op deze knoppen heeft als effect dat de big data addon aan de globale applicatie YAVV de instructie geeft om de aan die dag gerelateerde lijst met bestanden te openen. Dat openen verloopt vervolgens geheel los van het openstaande indexatie document. Er wordt dus een nieuw en losstaand document geopend, wat verder geen verband houdt met de indexatie. Zie voor een goed begrip van het concept “Document” binnen YAVV, alsook de relatie tussen “Documenten” en “Werkbladen”, dit artikel.
Het feit dat er geen relatie bestaat tussen het nieuw geopende document en het map-document is met name relevant voor de configuraties: de big data addon zoekt naar configuraties in de geïndexeerde map en alle onderliggende mappen, alsook in de default map voor configuraties indien die is ingesteld (zie hier TODO). Bij openen van bestanden uit een onderliggende map door YAVV zelf gebeurt dit echter niet, dan geldt het de reguliere manier waarop naar configuraties wordt gezocht.
In de praktijk betekent dit:
Wijzigingen aan configuraties binnen een map-document komen niet terug in een reguliere fasenlog die middels de knoppen in het indexatie werkblad wordt geopend.
Wil je vanuit de big-data addon snelle toegang tot de fasenlog per dag, dan is het handig eenmalig een configuratie te maken en deze op te slaan op de default locatie, waarna YAVV de configuratie zal gebruiken bij openen van de fasenlog van een specifieke dag.
Trend analyse over 2 maanden data: met YAVV/bd klaar in 1 minuut!
Aanleiding
YAVV big data maakt het mogelijk met YAVV te werken met grote hoeveelheden data.
YAVV is in eerste instantie gemaakt voor het werken met bestanden. De applicatie leest dan data uit één of meer bestanden en kan die data visualiseren (fasenlog, DSI op kaart) en analyseren (intensiteiten, roodrijders, etc.). Het uitgangspunt hier is dat het gaat om data die een aangesloten periode bestrijkt.
Gezien deze opzet is YAVV in de basis met name geschikt om te werken met data per dag, of wellicht enkele dagen. Gemiddelden tussen dagen, of het verloop van een bepaalde indicator over een langere periode, zijn in principe op te halen, maar dit vergt zeker bij veel data erg veel handwerk op, kost veel tijd, en is foutgevoelig.
Tegen die achtergrond is het idee ontstaan om binnen YAVV het werken met grotere hoeveelheden data mogelijk te maken. De “big data” addon voor YAVV is hiervan het resultaat.
Let op: YAVV/bd (ofwel de big-data addon voor YAVV) vormt een apart onderdeel van YAVV en vergt een aanvullende licentie.
Big data in een notendop
Met de big data addon wordt het mogelijk te werken met mappen waarin grotere hoeveelheden VLOG data aanwezig is. In een notendop werkt dit als volgt:
De gebruiker kiest een map van schijf
YAVV doorloopt recursief (dat wil zeggen inclusief onderliggende mappen) alle bestanden uit deze map.
Bij VLOG bestanden (.vlg of .vlog) wordt de inhoud geïndexeerd. Daarbij wordt het volgende uitgelezen:
kruispunt ID
start moment van de data in het bestand (er wordt dus in de data gekeken, de bestandsnaam en locatie in de mappenstructuur is hierbij niet relevant)
einde moment van de data in het bestand
aantallen fasen/detectoren/ingangen/uitgangen
Op basis van de indexatie data deelt YAVV data toe aan één of meer kruispunten.
Per kruispunt wordt de beschikbaarheid van data in de tijd berekend.
Tevens wordt bepaald welke configuraties er in de data zitten (op basis van de aantallen IO) en over welke periode deze geldig zijn.
Dit is van belang wanneer bv. het aantal fasen of detectoren op een bepaald moment binnen het bereik van de data wijzigt.
Na indexatie kan een selectie van dagen worden gemaakt (behorende bij één configuratie). Over de selectie kan vervolgens een trend analyse worden uitgevoerd: gemiddelde waarden over langere tijd, en het verloop van waarden over meerdere dagen.
Verder lezen
Rond de big data addon zijn er nog diverse artikelen beschikbaar op de wiki:
De big-data addon is speciaal ontworpen om met grote hoeveelheden data te werken. YAVV maakt daarbij zoveel mogelijk gebruik van de mogelijkheden van moderne processoren: zo wordt data bijvoorbeeld parallel doorgerekend. Hierbij is veel zorg besteed aan efficiënte en optimalisatie van het gebruik van systeembronnen. Daarnaast wordt waar mogelijk rekening gehouden met de limieten van het betreffende systeem.
Hieronder toch een aantal opmerkingen rond performance en geheugengebruik:
Werken met veel data vergt hoe dan ook veel van het systeem. Het is dus raadzaam gedurende indexatie en analyse geen andere zware taken uit te voeren op het betreffende systeem.
Hoewel mogelijk binnen YAVV, wordt afgeraden gelijktijdig meerdere trend analyses te draaien, of gedurende een trend analyse een indexatie uit te voeren. Veel sneller zal het hierdoor niet gaan, maar de kans op te weinig geheugen wordt wel groter.
YAVV houdt enige rekening met de hoeveelheid beschikbaar geheugen. In uitzonderlijke gevallen kan het gebeuren dat de applicatie daar toch te weinig van heeft. Enige tips:
Gebruik indien mogelijk een 64 bits versie van YAVV
Voer voor zeer grote hoeveelheden data eventueel meerdere afzonderlijke trend analyses uit
YAVV/bd biedt de optie de trend analyse single-threaded uit te voeren. Hoewel langzamer, kost dit doorgaans beduidend minder geheugen.